I had been toying around with writing SQL code to redraft one of the most talent rich drafts in NBA history (my apologies to the 1984 and 2003 NBA drafts) and sharing the results on my YouTube channel. Fortunately, I had a serendipitous coding session with my good buddy Terence down in Austin who introduced me to a cutting-edge AI tool (i.e., Windsurf AI). This initial session fundamentally changed how I think about analytics and AI-assisted coding.
If you’re an NBA, data and SQL enthusiast, then the 2018 NBA draft represents a fascinating case study for retrospective analysis.
We’re talking about a class that produced MVP-caliber talents like Luka Dončić (originally 3rd), Trae Young (5th), and Shai Gilgeous-Alexander (11th). Not to mention Ironman style players like Mikal Bridges (who has never missed an NBA game in his career thus far) and the unexpected emergence of undrafted gems like Duncan Robinson.
Seven years of career data later, we have enough statistical evidence to ask the crucial question: If NBA front offices knew then what we know now, how would this draft unfold?
What I loved about having Windsurf AI as my co-pilot (no relation to Microsoft) is that it handled the heavy lifting while I focused on the strategic analysis. The term “vibe-coding” has entered the lexicon recently, and it is used as a means to let AI instantly translate one’s analytical vision into executable T-SQL code.
When using any generative AI tool, the key is feeding detailed, comprehensive prompts to the models (the more context you give these models, the better your output becomes).
The components of my prompt included the following (you can watch the full video if you want to hear me recite the entire prompt).
My comprehensive prompt included:
-- 1. Role definition (NBA GM + Statistical Expert + T-SQL Specialist)
-- 2. Clear objectives (redraft based on career performance)
-- 3. Data specifications (column names, data types, constraints)
-- 4. Business rules (handle undrafted players as position 0)
-- 5. Output requirements (normalized scores, impact analysis)I settled on a redraft approach based upon a Career Impact Scoring methodology:
Impact Score Formula:
Points: 1.0x multiplier
Rebounds: 1.2x (slightly more valuable)
Assists: 1.5x (playmaking premium)
Steals/Blocks: 3.0x (defensive impact recognition)
Field Goal %: 100x multiplier
Free Throw %: 50x multiplier
Three-Point %: 100x multiplier
Games Played Bonus: Durability factor
Turnover Penalty: Subtracted from total score (my apologies Trae Young)Re-Draft Results:
Without spoiling the complete breakdown, I’ll share just enough to demonstrate the methodology’s power:
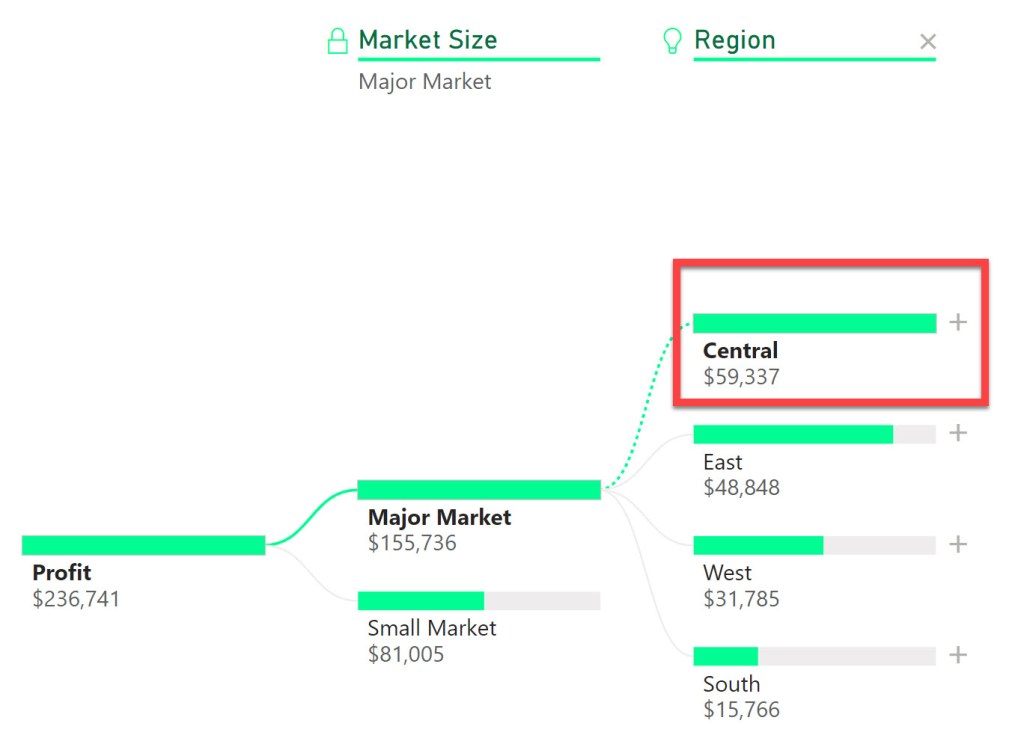
The most stunning result? Jalen Brunson emerged as the 5th overall pick in our AI-driven redraft, a player who originally went 33rd overall to Dallas.
If Brunson jumped from 33rd to 5th, imagine what happened to the other lottery picks. Some players who went in the top 10 dropped dramatically, while others who were considered “reaches” at the time proved to be incredible value picks.
Player Categorizations:
Although the AI initially suggested several player categories based upon their redrafted positions, I prompted the model to incorporate the specific logic and code I desired into the overall script (because I know how to write SQL).
Category Breakdowns:
- Massive Undrafted Steals: Players who weren’t drafted but earned first-round redraft positions
- Undrafted Steals: Players who weren’t drafted but earned a first or second-round redraft position
- Huge Steals: Late picks who jumped into a top 10 pick
- Steals: Later picks who jumped into the lottery
- Busts: Top 5 picks who fell to at least the 21st spot
- Major Busts: Top 10 picks who fell out of the first round entirely
- Expected Value: Players who performed roughly as anticipate
The Broader Implications for Data Professionals
For me, Windsurf served as a force multiplier and not a replacement for my SQL knowledge. It readily served as an amplifier of skills that I already possess. I still had to understand basic database concepts and a little query optimization in order to craft effective prompts and validate the model’s outputs. The difference between mediocre and exceptional AI-generated code lies in prompt quality, so put in the upfront time and effort to craft an initial prompt.
The Future of Analytics: Collaboration, Not Competition
In my opinion, this project undertaking represented something larger than a fun NBA analysis, it’s a glimpse into the future of data analysis work. We’re entering an era where analysts spend less time wrestling with syntax and more time on strategic thinking, hypothesis formation, domain knowledge, storytelling and insight communication.
We’re in this sweet spot right now where these types of agentic AI tools are assisting data analyses as opposed to fully completing data analyses. The key (right now, before the singularity) is embracing this transition rather than resisting it so you can remain ahead on the knowledge curve. Start experimenting with AI-assisted coding tools now, while the learning curve is manageable and the competitive advantage is still emerging.
Your Next Steps:
If you’re intrigued by the possibilities of AI-enhanced analytics, I encourage you to:
- Download Windsurf AI and experiment with your own datasets
- Practice prompt engineering with progressively complex analytical requests
- Combine your domain expertise with AI capabilities for unique insights
- Share your experiments to bolster your reputation and build your data portfolio
The full video walkthrough demonstrates every step of this process, from initial prompt crafting through final GitHub deployment.
In the full video you can discover which players claimed the top 4 spots in our redraft.
As always, get out there and do some great things with your data!
Join this channel to get access to perks: ► https://www.youtube.com/channel/UCL2ls5uXExB4p6_aZF2rUyg/join

Get the code and the data file used in the video here: ►
https://github.com/ASmoak/NBA_2018_ReDraft