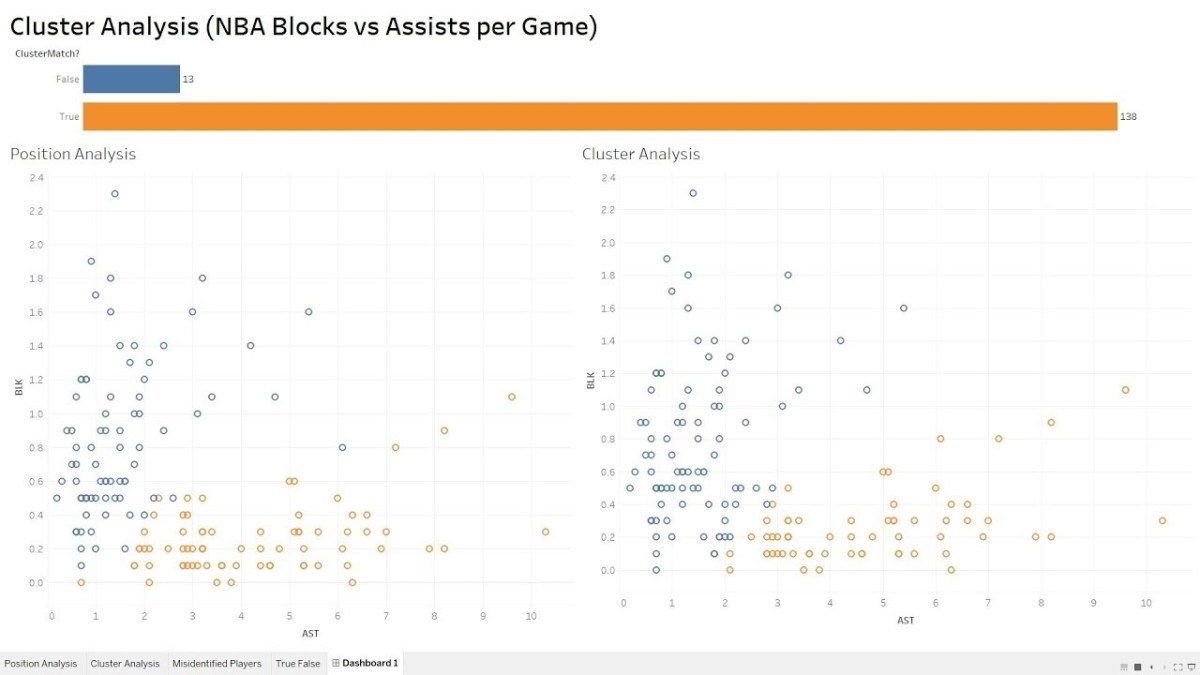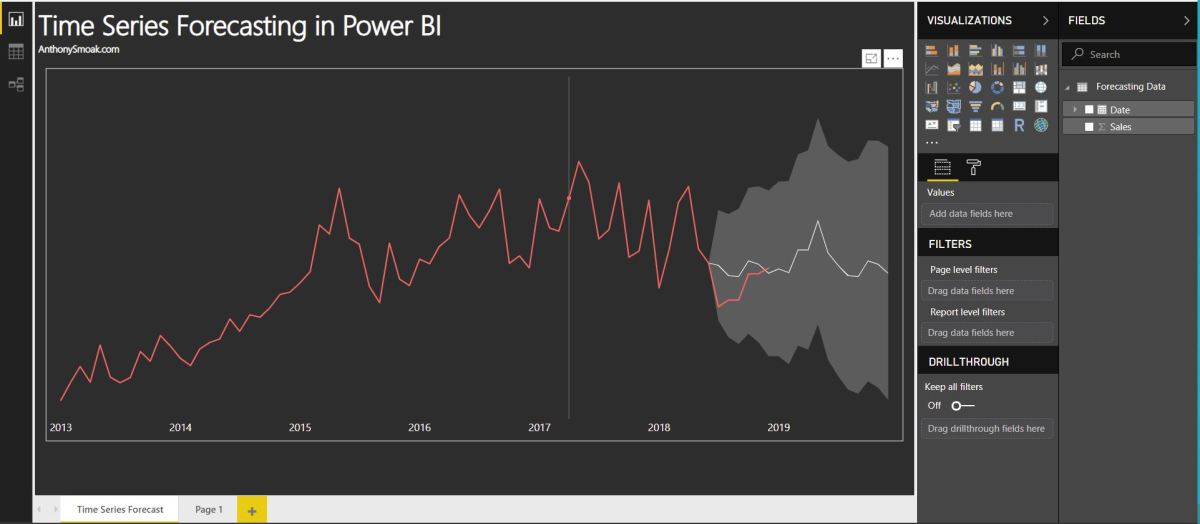
In this video I’ll demonstrate how to use the forecasting analytics option in Power BI. Although Power BI’s forecast algorithm is a black box, it’s more than likely using exponential smoothing to generate results. At a very high level, exponential smoothing is an algorithm that looks for patterns in data and extrapolates that pattern into the future. To help exponential smoothing perform at an optimal level, it is very important to pick an accurate seasonality estimation, as this will have an outsized effect on the time series forecast.
If your data points are at the daily grain, then you’d use 365 as your seasonality value. If your data points are at a monthly grain, then you’d use 12 as your seasonality value. Generally, the more seasonality cycles (e.g., years) that you provide Power BI, the more predictive your forecast will be.
Without giving away the whole video, here is a pro and a con of using forecasting in Power BI.
Con: As I stated earlier the exact algorithm is a black box. Although based upon a Power View blog post, we can reasonably assume exponential smoothing is involved. Furthermore, the results cannot be exported into a spreadsheet and analyzed.
Pro: The ability to “hindcast” allows you to observe if the forecasted values match your actual values. This ability allows you to judge whether the forecast is performing well.
Check out the video; I predict you’ll learn something new.
As always, If you find this type of instruction valuable make sure to subscribe to my Youtube channel.