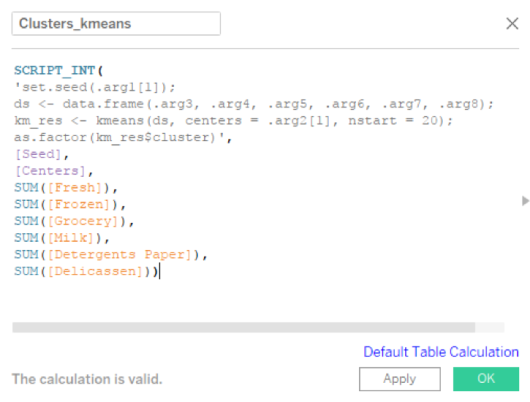
Once again I am digging into my digital crates to share an informative post. Here is a small writeup from a Syracuse graduate Enterprise Risk Management class (IST 625) I completed concerning JP Morgan Chase and the “London Whale”. The post is slightly edited from the final version I submitted. The assignment was as follows:
“This assignment requires you to research an organization that has suffered a devastating loss from a so-called ‘low frequency or low probability but-high consequence’ event, to understand what happened to that company during and after that event, and to synthesize what we can learn from their experiences.”
In gambling parlance, a whale is a high roller who bets big and has the potential to cause the house substantial losses if he/she stops betting at the wrong time. Although the whale at the center of this episode wasn’t sitting in a casino, the house (JPMorgan) experienced substantial losses when the betting stopped.
JP Morgan Overview
JPMorgan Chase is the largest financial holding company in the United Sates and has more than 2 trillion dollars in assets. It is also a global financial services firm with more than 250,000 employees (United States Senate pg. 24). The company has more than 5,600 branches and is a strong market participant in the mortgage lending, investment banking and credit card spaces (Hoover’s Company Records, 2014). JP Morgan’s principal bank subsidiary, JPMorgan Chase Banks is also the largest bank in the United States.
The current Chairman and CEO of JP Morgan Chase is Mr. James “Jamie” Dimon. Previous to 2012, Mr. Dimon’s name was associated with the eponymously named “Dimon principle”. “The ‘Dimon principle,’ as it is known, was shorthand for a safe bank with regular profits” (Ebrahimi, Aldrick & Wilson, 2012). With Mr. Dimon guiding the firm, JP Morgan held an excellent reputation with respect to risk management. The same could not be said of similar financial firms who were no longer “going concerns” as a result of the 2008 Great Recession.
“So when the US Government desperately sought someone with the balance sheet for the corporate rescue acts necessary to prevent financial meltdown, it sent for Dimon. In what were admittedly sweetened deals, JP Morgan swallowed bankrupt investment bank Bear Stearns and cash-strapped retail lender Washington Mutual” (Osborne, 2011). Emerging from the 2008 financial crisis unscathed, Mr. Dimon became more powerful and confident. He frequently railed against the need for government regulations with regard to proprietary trading in large financial firms. (Scuffham & Laurent, 2012) quote Mr. Dimon as stating, “We must not let regulatory reform and requirements create excessive bureaucracy and unnecessary permanent costs.”
Unfortunately for JP Morgan Chase and Mr. Dimon, subsequent trading events and risk management failures of 2011 would tarnish the firm and the CEO’s cultivated and highly regarded reputation.
London Whale Trades
(English, 2012) offers an analogy of the high risk/low frequency event that occurred in JP Morgan’s Chief Investment Office (i.e. CIO). Imagine a scalper who purchased 50,000 tickets to a sporting event with a capacity of 75,000 seats. The event is not nearly as popular as was anticipated by the scalper, thus the going price on the tickets plummets rapidly as would be ticket buyers wait for prices to fall further from face value. The scalper intended to hold tickets for the long term expecting high demand but with too many people on the sidelines betting that prices would fall, the scalper had to cut losses and sell at a drastic loss.
The “London Whale” trader at the center of this JP Morgan controversy was a French national and London based trader named Bruno Iksil who was known for being a successful leviathan risk taker. Mr. Iksil worked for the firm’s Chief Investment Office. Since JP Morgan has an excess of deposits after the firm makes loans available to business and consumers, this excess cash is invested by the CIO group to hedge against disparate investment actions undertaken by other areas of the bank.
The stated purpose of the CIO unit was to protect the bank from losses and interest rate risk by acting as a hedge and offsetting the bank’s other credit risks. The CIO unit is not tasked with proprietary or “prop” trading (essentially placing bets) intended to boost profits. Prop trading is the mandate of the company’s Investment Banking Division. In 2009 alone the CIO group’s Synthetic Credit Portfolio (SCP) of financial derivatives generated 1.05 billion dollars for the bank (United States Senate, pg.87). Ultimately JP Morgan would end up being a victim of its own success as it continued to conduct proprietary trades in the CIO division.
Bruno Iksil and the London CIO office were steadily racking up daily losses in the hundreds of millions of dollars by investing in synthetic derivatives (i.e. Credit Default swaps or CDS). The trading positions that the CIO office held were not hedging against other bank investments, as was the purported charge of this office. Credit default swaps are financial derivatives the provide investors insurance on bonds against potential default. Mr. Iksil, “has been selling protection on an index of 125 companies in the form of credit-default swaps. That essentially means he is betting on the improving credit of those companies, which he does through the index—CDX IG 9—tracking these companies” (Bianco, 2012, para 5).
Needless to say, the companies in the index did not improve. The initial 100 million dollar position that the CIO office held in the CDX IG 9 index was essentially cornering the market and when there were no willing buyers, the firm had to sell at massive loss.
In April of 2012 the press began running stories about the identity of the “London Whale”. The massively large trades in credit default swaps (the same complex financial instruments that doomed A.I.G during the 2008 financial crisis) began to affect credit markets worldwide. Initially, by the end of the week on May 11, 2012 when the firm held a hastily convened conference call regarding transparency around the London Whale trades, JP Morgan suffered a loss of 14.4 billion from its market capitalization as its stock price fell 11.47% in two days (Ebrahimi, Aldrick & Wilson, 2012). By the end of May the synthetic derivatives portfolio alone had lost 2 billion dollars. By the end of June the losses doubled to 4.4 billion and eventually reached 6.2 billion by the end of the year (United States Senate, pg. 12).
Initial Management Response
Once the CIO division management learned of Bruno Iksil’s precarious investment positions, “it could have announced the maximum possible losses from the trades. Instead it said what the losses were at that moment in time, and hoped a change in sentiment and some clever trading would stop them spiralling [sic]”. To the London Whale’s credit, once he observed the potential for disaster, he suggested that the division take a loss or “full pain” which would have been an additional 100 million dollars wiped out (Farrell, 2012), far less than the eventual 6.2 billion dollar total loss number.
Amazingly, Mr. Iksil’s management began to take actions that would conceal the magnitude of losses reported. Recorded telephone calls, instant messages and a shadow spreadsheet containing actual projected losses, revealed how traders were pressured to minimize the expected losses of the SCP (Synthetic Credit Portfolio) (United States Senate Report, pg. 20).
Internal CIO management also disregarded their own risk metrics such as the VaR or value at risk, which estimates the maximum risk of loss over the course of a day. This warning sign metric was ignored and then actually raised. CEO Jamie Dimon, Chief Risk Officer John Hogan and CIO head Ina Drew, “approved the temporary increase in the Firm-wide VaR limit, and Ms. Drew approved a temporary increase in CIO’s 10-Q VaR limit.” (JPMorgan Chase & Co, 2013 pg. 79)
Senior bank management was told that potential losses were massive and no longer functioned as a hedge to the bank; management then proceeded to downplay those issues until the losses mounted into the billions of dollars (United States Senate, pg.21). On an April 13, 2102 first quarter conference call CEO Jamie Dimon dismissed the initial publicity surrounding the London Whale trades by characterizing them as a “complete tempest in a teapot” (United States Senate pg. 17). By June 2013, Mr. Dimon’s stated to a Senate Panel on the trading losses, “Let me first say, when I made that statement, I was dead wrong” (PBS NewsHour, 2012).
Remediation and Outcomes
CEO Jamie Dimon stated, “CIO will no longer trade a synthetic credit portfolio and will focus on its core mandate of conservatively investing excess deposits to earn a fair return” (JPMorgan Chase & Co., 2012(a), pg. 3). Management instituted a number of changes as a result of the CIO trading imbroglio. All CIO managers based in London with any responsibility for the Synthetic Credit Portfolio were separated from the firm with no severance and without 2012 incentive compensation. (JPMorgan Chase & Co., 2012(a), pg.22).
JP Morgan instituted significant changes for the better in the CIO Risk Management organization. A new Chief Risk Officer was empowered to hire additional senior level officers to “extend the capacity of the Risk function within CIO, Treasury and Corporate, and he has made 20 such hires since May 2012” (JPMorgan Chase & Co., 2012(a), pg.114). Along with upgraded personnel skills in the CIO Risk organization, management rightfully instituted a common sense approach to structural issues.
In the pre “Whale trades” environment, the CIO Risk Committee met infrequently and did not contain any members from outside of the CIO organization. This lack of diversity in the realm of “risk-thought” fostered a group think/rubber-stamp mentality. CIO Risk managers did not feel “sufficiently independent” from the CIO business to ask hard questions or criticize trading strategies (JPMorgan Chase & Co., 2012(a), pgs. 12-13).
Industry Impact
“Dimonfreude” was a term coined in the wake of the trading losses, “it means taking great satisfaction in the misfortunes of the JPMorgan boss” (Foley, 2012). Yet, the fall out from JP Morgan’s episode was more than mere embarrassment for the firm and the CEO’s reputation in the area of risk management. To the chagrin of Mr. Dimon, this episode strengthened the case for more government oversight of the financial industry. In the words of then Treasury Secretary Timothy Geithner, “I think this failure of risk management is just a very powerful case for financial reform” (Shorter, Murphy & Miller, 2012, pg. 24).
References
Bianco, J. (2012). Understanding J.P. Morgan’s Loss, And Why More Might Be Coming. The Big Picture. Retrieved February 2, 2014, from http://www.ritholtz.com/blog/2012/05/understanding-j-p-morgans-loss-and-why-more-might-be-coming/
English, S. (2012). How London Whale’s errors attracted the market sharks. The Independent. Retrieved from Factiva.
Ebrahimi., H., Aldrick, P., & Wilson, H. (2012). The day JP Morgan’s Jamie Dimon lost his sparkle; Breathtaking risk failures at JP Morgan have left the bank’s reputation on the edge. The Telegraph Online. Retrieved from Factiva.
Farrell, M. (2013). JPMorgan slashes Dimon’s bonus by 53%. CNN Wire. Retrieved from Factiva.
Foley, S. Jamie Dimon Chief executive, JP Morgan Chase (2012). The Independent. Retrieved from Factiva.
Hoover’s Company Records. (2014). JPMorgan Chase & Co. Austin, U.S. Retrieved from http://search.proquest.com.libezproxy2.syr.edu/docview/230565788?accountid=14214
JPMorgan Chase & Co. (2012)(a). JPMORGAN CHASE REPORTS SECOND-QUARTER 2012 NET INCOME OF $5.0 BILLION,OR $1.21 PER SHARE, ON REVENUE OF $22.9BILLION. Retrieved February 1, 2014 from http://files.shareholder.com/downloads/ONE/2939707738x0x582870/6a286dff-ad7e-40ba-92ef-e6ff1b3be161/JPM_2Q12_EPR_Final.pdf
JPMorgan Chase & Co. (2012)(b). CIO Task Force Update. Retrieved February 1, 2014 from http://files.shareholder.com/downloads/ONE/2939707738x0x582869/df1f2a5a-927e-4c10-a6a5-a8ebd8dafd69/CIO_Taskforce_FINAL.pdf
JPMorgan Chase & Co. (2013). Report of JPMorgan Chase & Co. Management Task Force Regarding 2012 CIO Losses. Retrieved February 1, 2014 from http://files.shareholder.com/downloads/ONE/2272984969x0x628656/4cb574a0-0bf5-4728-9582-625e4519b5ab/Task_Force_Report.pdf
Osborne, A. (2012). JP Morgan $2bn loss: Dimon’s in the rough; Be careful what you wish for. The Telegraph Online. Retrieved from Factiva.
PBS NewsHour. JPMorgan Chase’s Big Losses, Big Risk: Blip on Radar or Systemic? Retrieved February 1, 2014 from http://www.pbs.org/newshour/bb/business-jan-june12-jamiedimon_06-13/
Scuffham, M. & Laurent, L. (2012). Trader known as ‘London Whale’ for his huge, hidden bets. The Globe and Mail. Retrieved from Factiva.
Shorter, G., Murphy, E., Miller, R. (2012). JP Morgan Trading Losses: Implications for the Volcker Rule and Other Regulation. Congressional Research Service. Washington, DC. Retrieved from https://www.fas.org/sgp/crs/misc/R42665.pdf
United States Senate. (2013). JPMorgan Chase Whale Trades: A Case History of Derivates Risks And Abuses. Staff Report. Washington, DC. Retrieved from http://www.hsgac.senate.gov/download/report-jpmorgan-chase-whale-trades-a-case-history-of-derivatives-risks-and-abuses-march-15-2013
This post does not necessarily represent the views of my employer and is solely my own analysis as required for a graduate school short assignment.
Picture Copyright : Andrey Kiselev on 123rf.com