Whenever I have to fire up SQL Server to perform some analyses there are a few functions, keywords and capabilities that I always find myself referring to in order to analyze my data. As is the case with most T-SQL users, even those of us that have been using T-SQL for over a decade, in our heads we always know what we want to do but will refer to our favorite syntax reference sources in order to progress. I decided to make a handy reference sheet for myself and then decided to post it here for anyone else.
How to Create a Temporary Table in T-SQL / SQL Server
Temporary (i.e., temp) tables enable the storage of result sets from SQL scripts yet require less record locking overhead and thus increase performance. They remain in effect until they are explicitly dropped, or until the connection that created them is discontinued.
As I see it, their main benefit is that they preclude me from writing difficult to comprehend nested queries since I can place a result set inside a temp table and then join it back to a normal table at-will.
In this example, the results of permanent table ‘TABLE1’ will be placed into global temporary table ##TEMPTABLE:
SELECT
FIELDNAME1,
FIELDNAME2,
FILEDNAME3
INTO ##TEMPTABLE
FROM TABLE1
Temp tables are stored in the tempdb system database.
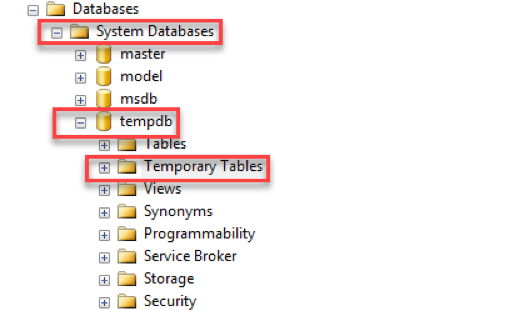
“The tempdb system database is a global resource that is available to all users connected to the instance of SQL Server or connected to SQL Database.”
Additional Reference:
What do the Hashtags Mean in T-SQL Temp Table Creation?
The number of hash signs “#” preceding the name of the temp table affects whether the scope of the table is local or global.
- If you precede the temp table name with “#”, then the table will be treated as a local temp table.
- If you precede the temp table with “##”, then the table will be treated as a global temp table.
“You can create local and global temporary tables. Local temporary tables are visible only in the current session, and global temporary tables are visible to all sessions. Temporary tables cannot be partitioned. Prefix local temporary table names with single number sign (#table_name), and prefix global temporary table names with a double number sign (##table_name).”
Additional References:
How to Drop a Temp Table in T-SQL / SQL Server
There are times when you will need to rerun code that creates a temp table. If the temp table has already been created, you will encounter an error.
“There is already an object named ‘##TEMP_TABLE_NAME’ in the database.”
Place the following code above the creation of your temp tables to force SQL Server to drop the temp table if it already exists. Change ##TEMP_TABLE_NAME to your table name and use the correct number of hashtags as applicable to a local (#) or global (##) temp table.
IF OBJECT_ID('tempdb..##TEMP_TABLE_NAME') IS NOT NULL
DROP TABLE ##TEMP_TABLE_NAME
How to Add a New Field to a Temp Table in T-SQL / SQL Server (ALTER TABLE)
Here is example T-SQL that illustrates how to add a new field to a global temp table. The code below adds a simple bit field (holds either 1 or 0) named FIELD1 to the temp table, declares it as NOT NULL (i.e., it must have a value) and then defaults the value to 0.
ALTER TABLE ##TEMP_TABLE
ADD FIELD1 Bit NOT NULL DEFAULT (0)
The following code changes the data type of an existing field in a global temp table. FIELD1 has its data type changed to NVARCHAR(2) and is declared as NOT NULL.
ALTER TABLE ##TEMP_TABLE
ALTER COLUMN FIELD1 NVARCHAR(20) NOT NULL;
Additional References:
How to Use a CASE Statement in T-SQL / SQL Server
The following information on the CASE statement is direct from Microsoft:
The CASE expression evaluates a list of conditions and returns one of multiple possible result expressions. The CASE expression has two formats:
- The simple CASE expression compares an expression to a set of simple expressions to determine the result.
- The searched CASE expression evaluates a set of Boolean expressions to determine the result.
Both formats support an optional ELSE argument.
CASE can be used in any statement or clause that allows a valid expression. For example, you can use CASE in statements such as SELECT, UPDATE, DELETE and SET, and in clauses such as select_list, IN, WHERE, ORDER BY, and HAVING.
Examples from Microsoft:
SELECT
ProductNumber,
Category =
CASE ProductLine
WHEN 'R' THEN 'Road'
WHEN 'M' THEN 'Mountain'
WHEN 'T' THEN 'Touring'
WHEN 'S' THEN 'Other sale items'
ELSE 'Not for sale'
END,
Name
FROM Production.Product
ORDER BY ProductNumber;
SELECT
ProductNumber,
Name,
"Price Range" =
CASE
WHEN ListPrice = 0 THEN 'Mfg item - not for resale'
WHEN ListPrice = 50 and ListPrice = 250 and ListPrice < 1000 THEN 'Under $1000'
ELSE 'Over $1000'
END
FROM Production.Product
ORDER BY ProductNumber ;
Here is a link to great post that highlights some of the unexpected results when using the CASE statement.
How to Use the Cast Function in T-SQL / SQL Server
When you need to convert a data field or expression to another data type then the cast function can be helpful. I typically have the need to take imported text fields and evaluate them as a datetime. The cast statement below helps me resolve this issue.
Select cast(txtOrder_Date as datetime) as Order_Date
This statement can also be used in a WHERE clause to filter the text as if it were a true datetime field/.
Where cast(txtOrder_Date as datetime)) between '20170101' and '20181231'
Furthermore, you can cast a literal string to an integer or decimal as needed.
Select cast(‘12345’ as int) as Integer_Field
Select cast(‘12345.12’’ as decimal (9,2)) as Decimal_Field
When your FIELDNAME is a text value, you can use the cast function to change its data type to an integer or decimal, and then sum the results. Here are a few examples I have had to use in the past with the sum function.
sum(cast(FIELDNAME as int)) as Sum_Overall_Qty
sum(cast(ltrim(rtrim(FIELDNAME2)) as decimal(38,2))) as Sum_Sales_Price
Additional Reference:
Using the REPLACE Function in T-SQL / SQL Server
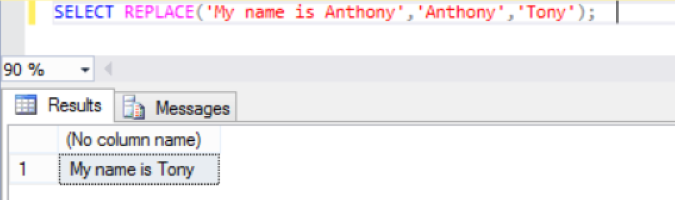
The Replace function is useful when you need to replace all occurrences of one character or substring with another character or substring. The following select will replace the string ‘Anthony’ with ‘Tony’.
Select REPLACE(‘My name is Anthony’, ‘Anthony’, ‘Tony’);
Additional Reference:
How to Convert a Negative Text Number in Parenthesis Format to a Numeric Data Type (T-SQL / SQL Server)
I’ve found this particular expression useful when trying to convert a negative number in text format to a decimal value when the text is enclosed in parentheses; i.e., changing (123.45) to -123.45
It makes use of the REPLACE function to find the leading parenthesis and replace it with a negative sign. This first REPLACE is nested inside another REPLACE function in order to find the trailing parenthesis and replace
Select cast(replace(replace('(123.45)','(','-'),')','') as money);
You can also use the convert function to accomplish the same result. Below I used this line of code to sum the negative formatted text (represented by FIELD_NAME) by converting it to the money data type after replacing the parenthesis.
sum(convert(money,replace(replace(FIELD_NAME,'(','-'),')',''))) as Sum_Domestic_Price
COALESCE Function in T-SQL / SQL Server
The COALESCE function is very useful when replacing NULL field values with a substitute value. Per Microsoft, the COALESCE function evaluates in order a comma delimited list of expressions and returns the current value of the first expression that initially does not evaluate to NULL.
For example,
SELECT COALESCE(NULL, NULL, 'third_value', 'fourth_value');
returns the third value because the third value is the first value that is not null. I will use the COALESCE function at times to replace NULL values with 0 for use in calculations.
Select COALESCE(NULL_FIELD, 0)
https://docs.microsoft.com/en-us/sql/t-sql/language-elements/coalesce-transact-sql?view=sql-server-2017