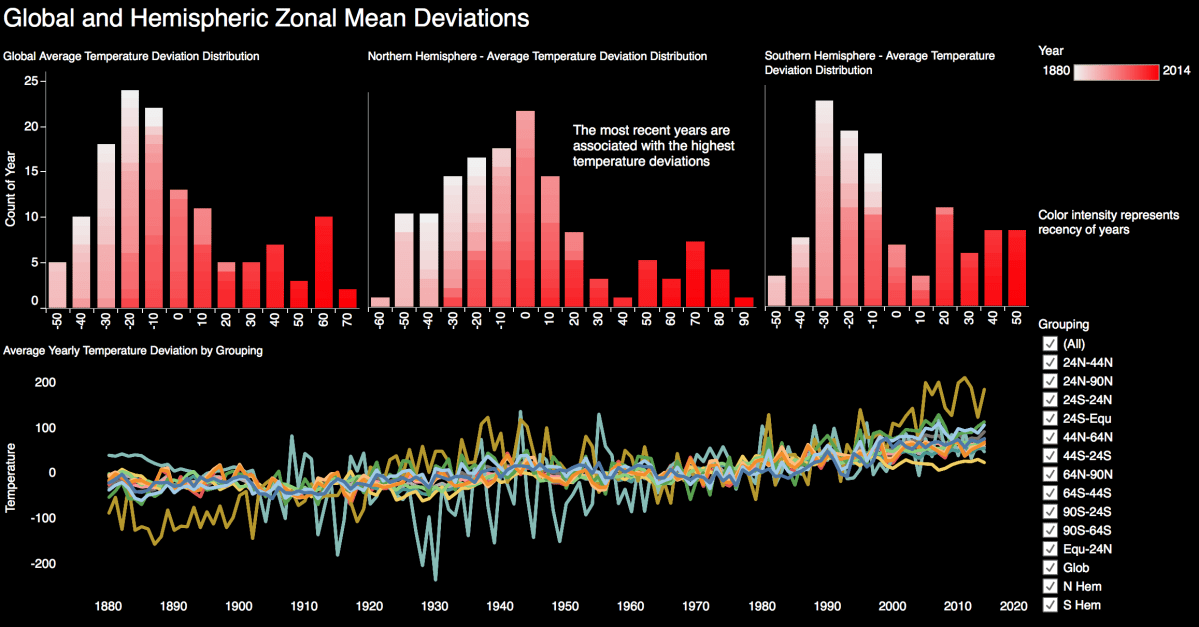
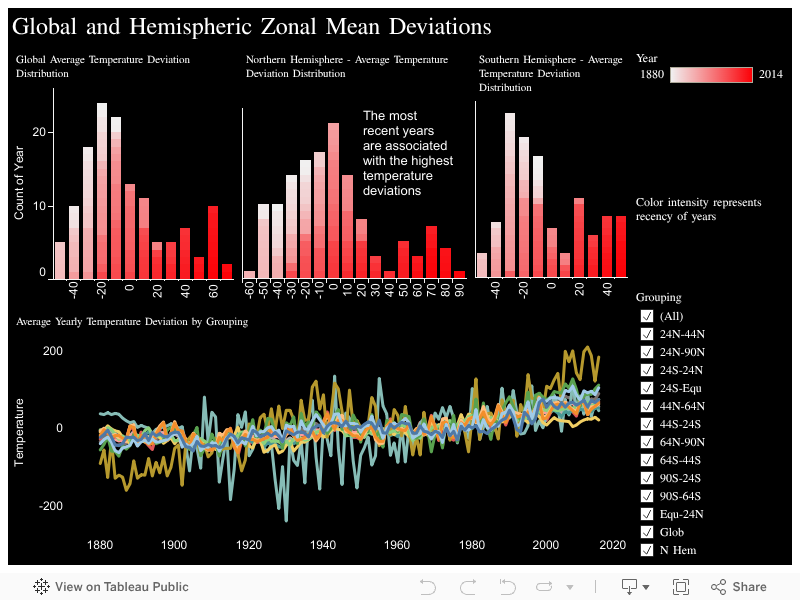
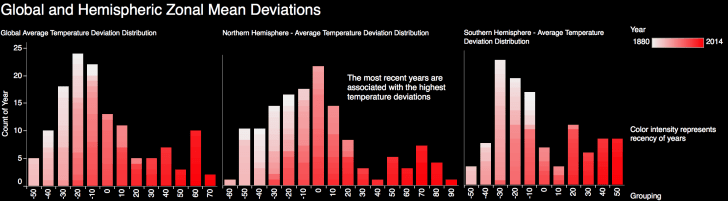
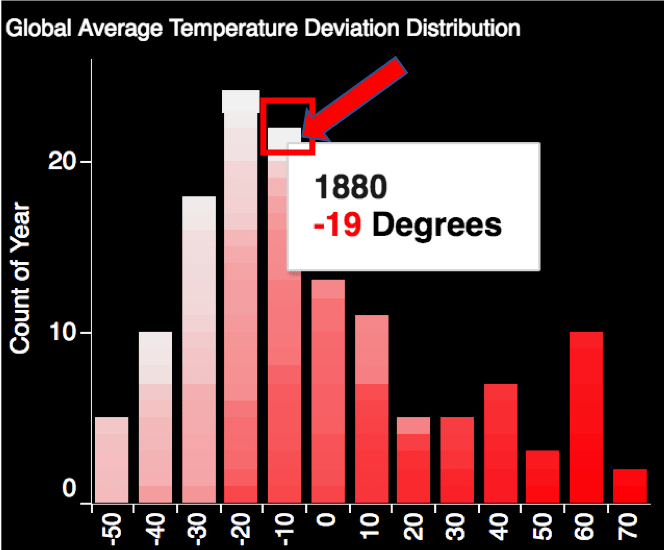
This following is a guest post.
Clustering:
Clustering is the grouping of similar observations or data points. Tableau enables clustering analysis by using the K-means model and a centroid approach. This model divides the data into k segments with a centroid in each segment. The centroid is the mean value of all points in that segment. The objective of this algorithm is to place centroids in segments such that the total sum of distances between centroids and points in their segments is as small as possible.
In this post we will demonstrate some of clustering’s practical applications using Tableau. To get started, download the dataset from this link.
Let’s get our hands dirty!
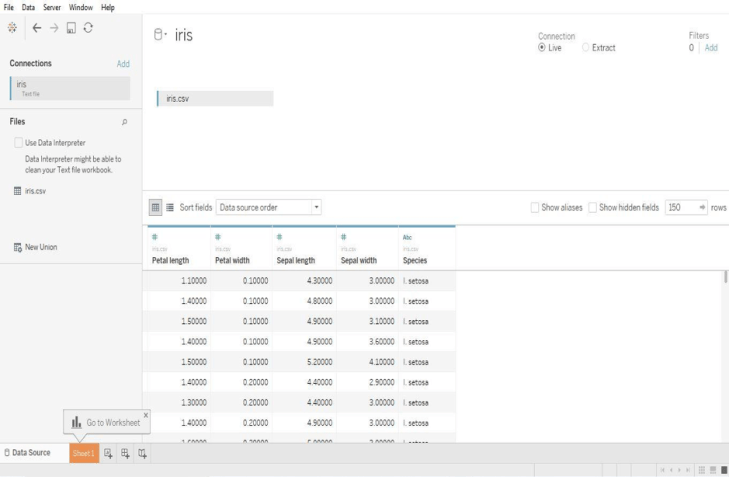
Examine the data-set, it contains data about different characteristics of flowers. Once the data is loaded into Tableau it will look like the screenshot below.
Now let’s plot a visualization between petal width and length. Just drag and drop the petal width and length onto rows and columns as shown below.
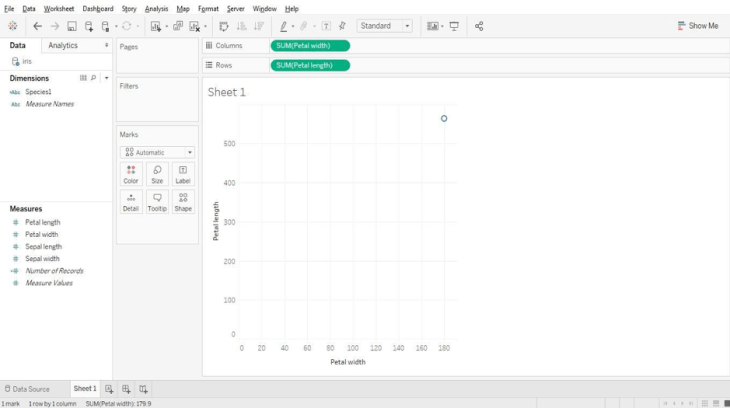
Here we see that there is only one data point as Tableau by default aggregates measures. We can “un-aggregate” the data with a click as shown below.
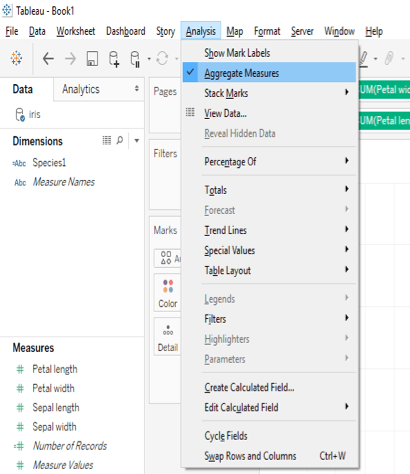
Just go to the analysis tab in the menu and un-tick the aggregate measures option.

Now we can observe a scatter plot of two measures. Let’s cluster these data points according to their species by navigating to the analytics pane as shown below.
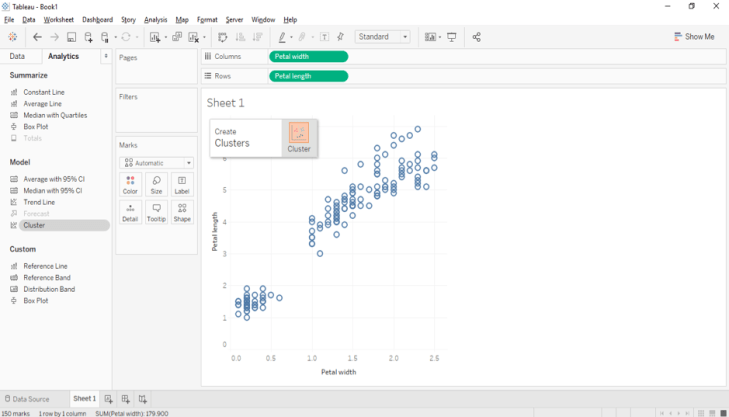
Drag and drop the cluster option on to the plot.
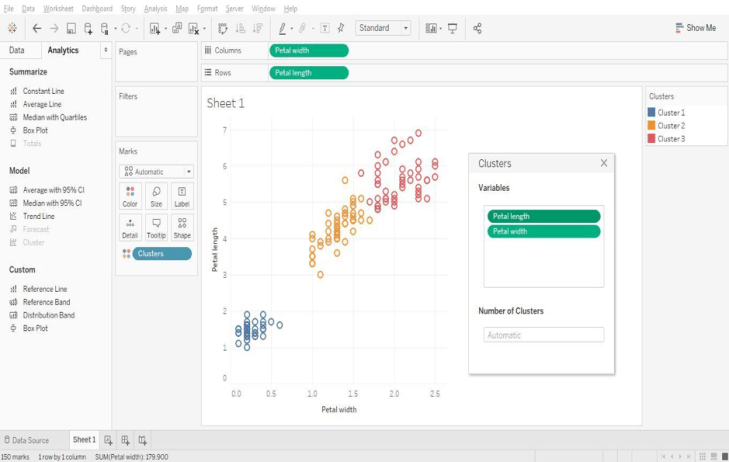
Clusters are formed automatically, although there is an option to change the number of clusters. Users can also select the variables used for cluster generation, although Tableau uses the fields in the view to form the initial clusters.

We can visually observe the clusters and Tableau provides a handy option that displays cluster statistics.
Click on the “describe clusters” option to observe a summary and model description.
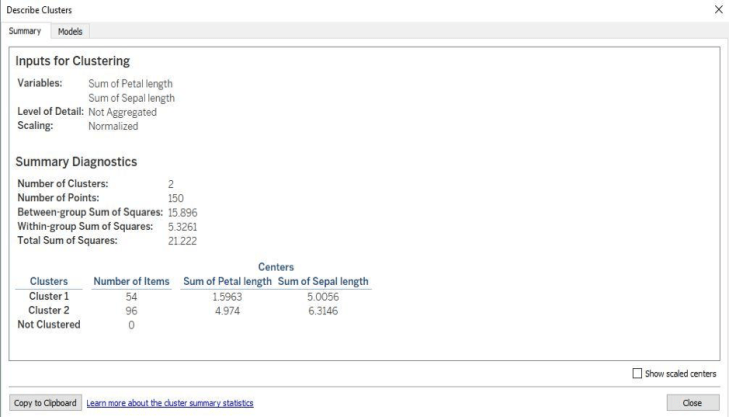
The summary tab provides a high level overview of the variables used in the model and various sum of squares information. Let’s turn our attention to the models tab and the main generated statistics.
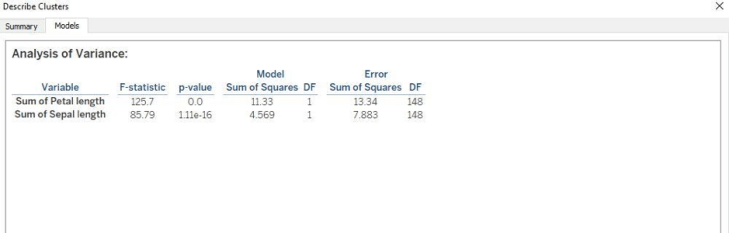
F-Ratio:
The F-Ratio is used to determine if the expected values of a variable within groups differ from one another. It is the ratio of sum of squares (variances).
F= Between Group Variability/Within Group Variability
The greater the F-statistic, the better the corresponding variable in distinguishing between clusters.
P-Value:
In a statistical hypothesis test the P-value helps you determine the significance of your results. The p-value is the probability that the F-distribution of all possible values of the F-statistic takes on a value greater than the actual F-statistic for a variable. If the p-value falls below a specified significance level, then the null hypothesis can be rejected. The lesser the p-value, then more the expected values of the elements of the corresponding variable differ among clusters.
Tableau provides an option to save formed clusters into a group that can be used for subsequent analyses. Simply drag and drop the cluster from the marks pane to the dimensions section to save it as group.
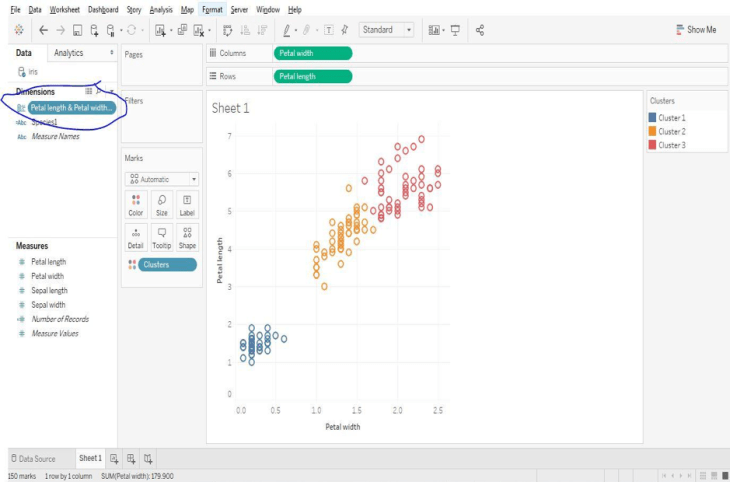
Tableau doesn’t allow clustering on these types of fields:
- Dates
- Bins
- Sets
- Table Calculations
- Blended Calculations
- Ad-hoc Calculations
- Parameters
- Generated Longitude and Latitude Values
Let’s look at another example using the default World Indicators data set that comes with Tableau. Open the sample workbook named World Indicators and explore the data regarding various countries.
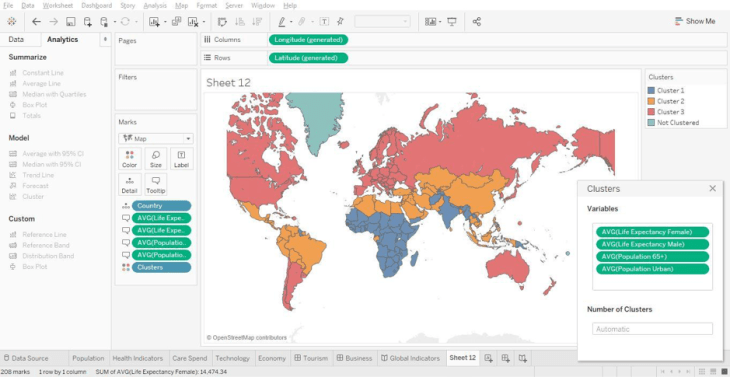
Try using different variables to form clusters. Use the model description to learn about the various countries based upon their clusters.

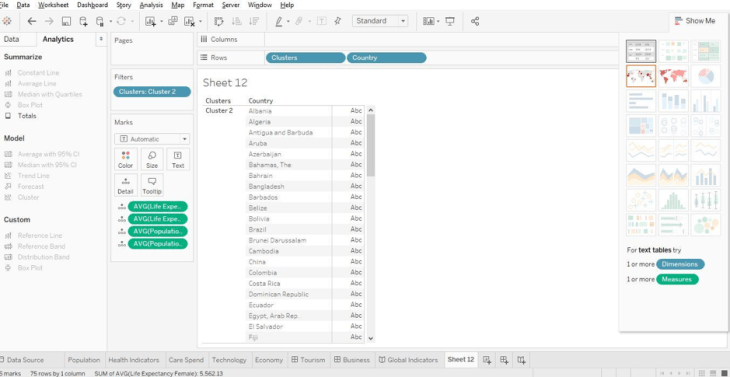
Here it shows average life expectancy, average population above 65 years and urban population. These statistics provide insight into the composition of the particular clusters. We can see which countries comprise each cluster as shown below. Select any cluster and go to the “Show Me” tab and select text “Table” to view the names of each country present in a cluster.
Conclusion:
We’ve only covered a few scenarios using clustering and how it aids with the segmentation of data. Clustering is an essential function of exploratory data mining. Keep exploring the results of cluster analysis by using different types of data sets. Keep Rocking!
“Happy Clustering!!”
Author Bio
This article was contributed by Juturu Pavan, Prudhvi Sai Ram, Saneesh Veetil and Chaitanya Sagar contributed to this article.