The LEAD and LAG window functions in SQL offer the simple yet powerful ability to analyze data beyond the current row. They allow you to access values from rows before and after the current one, without using complex self-joins or subqueries. You can use these two functions to compare values across rows, calculate differences, and perform other operations that require looking ahead or behind in your dataset.
Back when I used Microsoft Access as my main data tool and needed to access information from a previous row to do calculations, I would use VBA coding to implement solutions. At the time, it did not occur to me that I could achieve similar functionality using SQL Server’s LEAD and LAG window functions.
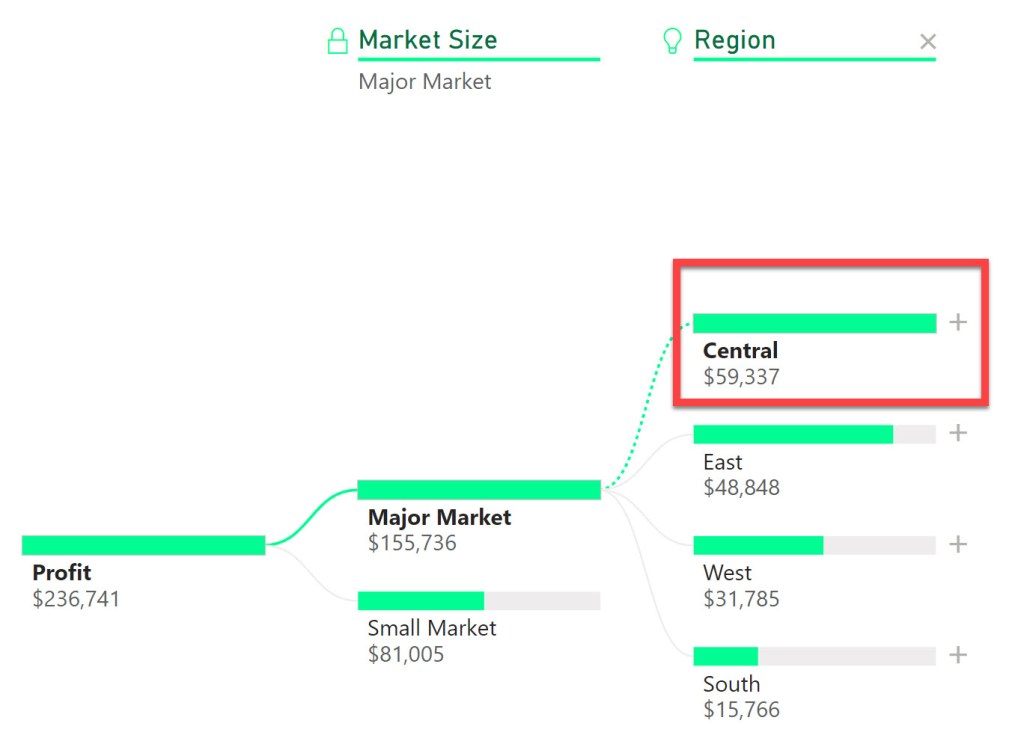
In this highly informative video (if I do say so myself, I’m biased but I’m correct), I show you a use case for the LAG function to calculate the average time for an invoice to move through approver workflow steps. At a high level, this entails subtracting the approval date from a prior row from the current row’s approval date.
LEAD & LAG Window Function Syntax
The LAG window function allows you to access data from a prior row to “look back” dynamically as you query data. This aids calculating deltas, running totals, and more. The syntax of LAG function is as follows:
LAG(column_name, offset, default) OVER (PARTITION BY column_name ORDER BY column_name)The LEAD window function allows you to access data from an upcoming row to “look ahead” dynamically as you query data. The syntax of LEAD function is as follows:
LAG(column_name, offset, default) OVER (PARTITION BY column_name ORDER BY column_name)The PARTITION BY clause is key; it that ensures we only look back (or ahead) within a given value in the column_name (for example as shown in the video, an invoice number) otherwise row transitions would provide invalid lookups.
Why Use Lead and Lag functions in SQL?
Using LEAD and LAG functions in SQL can help you analyze your data faster and easier, because you can:
- Perform calculations and comparisons across rows without using self-joins or subqueries, which can be complex and slow.
- Avoid exporting your data to Excel or other tools, which can be time-consuming and error-prone.
- Simplify your code and improve its readability and maintainability.
As I mentioned earlier, if I had known about these two functions years ago when I was trying to access prior values via VBA and loops, I could have saved myself a lot of time, increased my efficiency and made my approach much easier to read in the resulting documentation.
Conclusion
I believe that learning from examples is critical for mastering both logical concepts and SQL syntax. By watching the linked video, you will gain the knowledge to tackle similar problems in your own data analysis scenarios.
Additionally, LEAD and LAG provide simpler, set-based solutions for cross-row data comparisons that would otherwise require procedural coding.

I appreciate everyone who has supported this blog and my YouTube channel via merch. Please check out the logo shop here.
If you want to learn all the latest tips and tricks in core data analysis tools, stay in contact with me through my various social media presences.
Thank you!!
Anthony B Smoak